
It was a snowy night in Edmonton, the clock was ticking past 1 am, and I was busy working on developing a mathematical model for my graduate studies thesis. After spending hours making changes to my source code, I finally ended up with a working script, which functioned perfectly. I went to bed with everything set to share this important update with my research group. The next morning, I woke up to this window on my laptop:
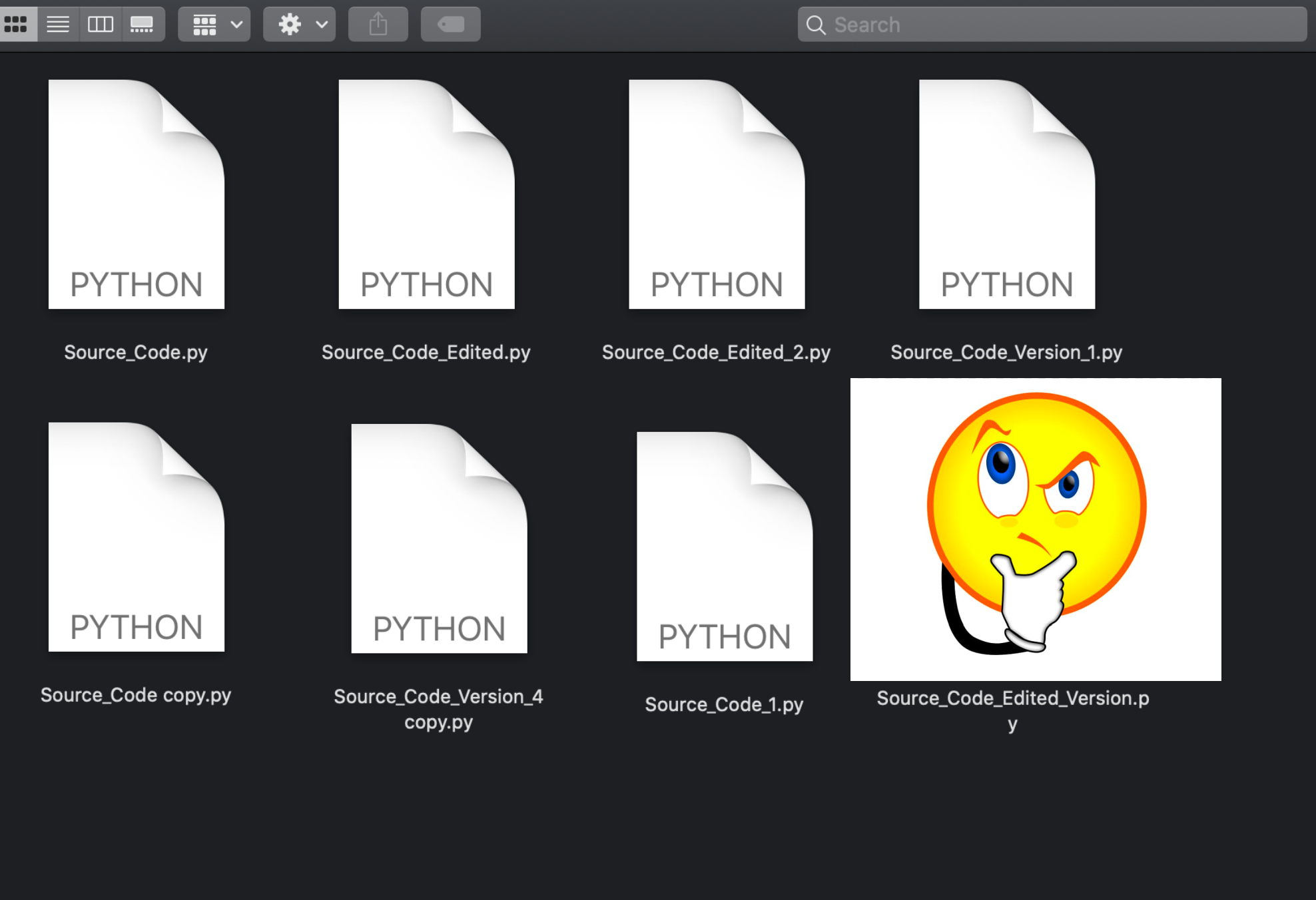
Screenshot of a window on my laptop.
I had started making changes to the file ‘Source_Code.py’. In the process of modifying the code, I ended up creating 8 different copies of the ‘Source_Code.py’. While these 8 copies were different attempts to debug the code, I completely lost track of all the changes that I did. It took me a while to figure out what each code meant. Did I miss something obvious here? Could I have used any other tool to make my workflow better?
If you have ever experienced this in your grad/work life, worry not! I’d like to introduce you to Version Control using Git. Git is an open-source version control tool widely used by software developers for tracking the history of changes made locally to a file. It connects to Github, a cloud-based service that allows you to take the work that you did offline in a Git repository into an online space, where you can work collaboratively as a team.
To understand the workings of Git and Github, let’s consider a software company consisting of three developers who are trying to add extra features to an existing product. Each developer has a Git project repository in their local machine, and part of a central repository in Github to work collaboratively (as described in figure 1). It is easier to understand the workflow in Git/Github using a tree analogy. The Master branch in Github is analogous to the trunk of the tree, and there are different branches from the Master that represent different versions/tasks.
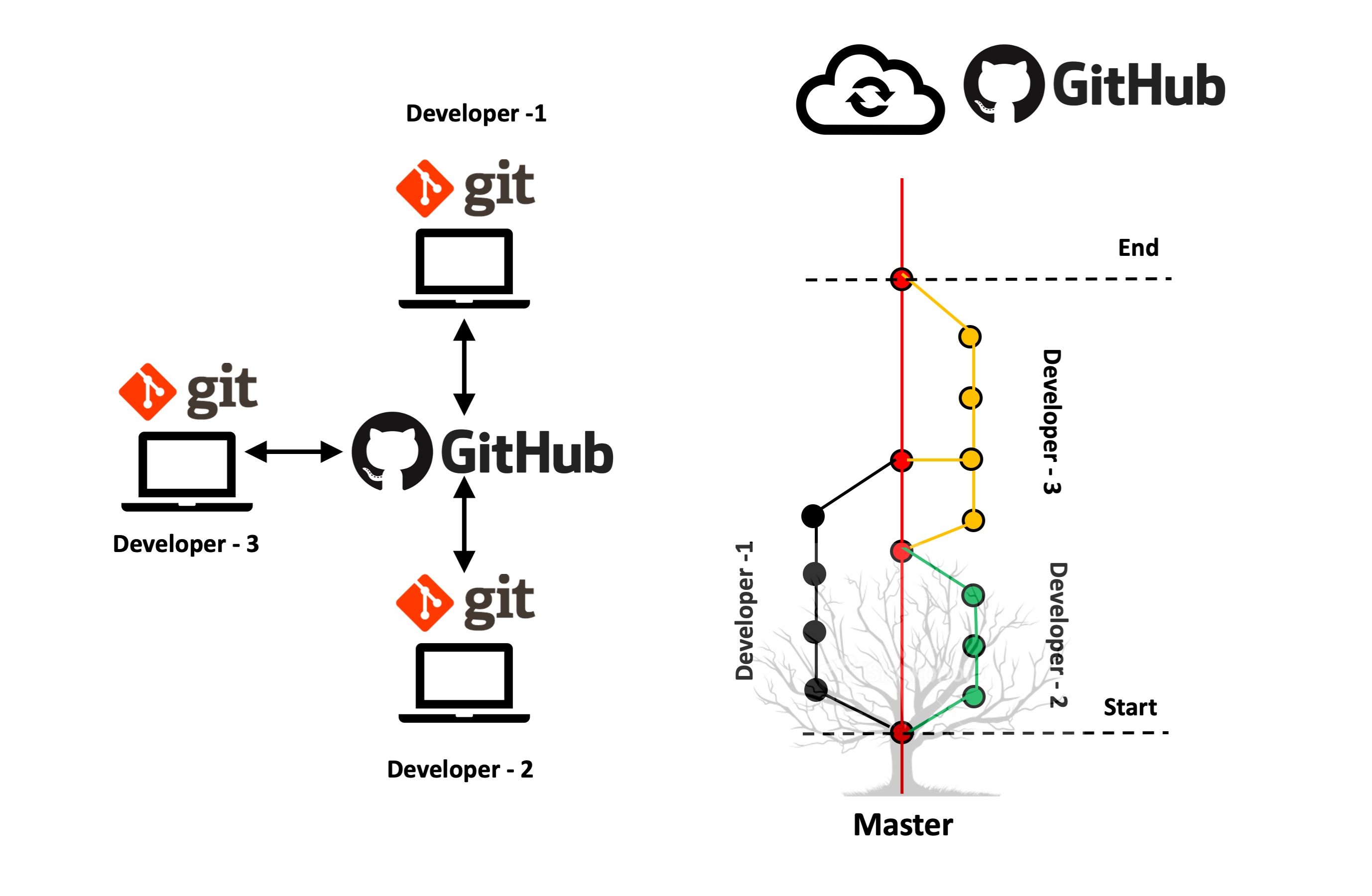
Figure 1: Schematic representation of how Git/Github works.
As described in the figure, at the start of the project, Developer - 1 and Developer - 2 work independently on their allotted tasks by branching out from the Master. Developer - 2 works fast and finishes the given task, and then merges the completed work back with the Master branch. Developer - 3 then takes over by creating a new branch. During that process, they also fetch the work completed by Developer - 1. The real advantage of Git/Github is that, even if Developer - 3 decides to experiment with the code in the branch they created, there is alwasy a working copy sitting in the Master branch that they can go back to. Each marker in figure 1 and figure 2 represents the changes made to the code (in Git terminology, they are called ‘commits’). A typical commit has a unique ‘commit id’, along with information about its name and the time the particular change was made. With this unique commit id, it’s possible to go back and forth with the code. This process is described in figure-2. Note: we are not creating new copies here, but are just travelling back and forth between the versions of the same piece of code.
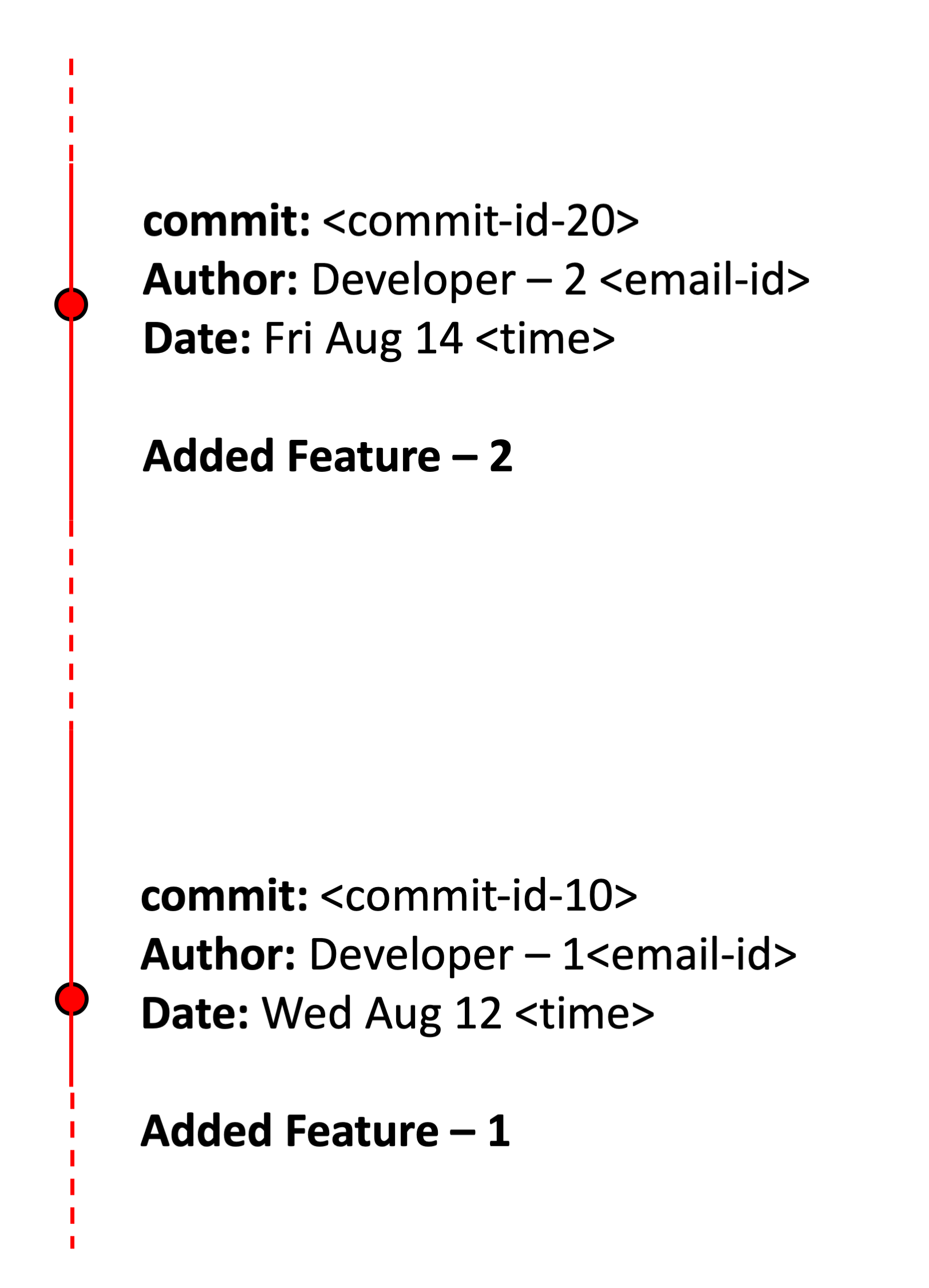
Figure 2: Schematic of the commit logs in Git/Github.
While this collaborative workflow using Git/Github is the most common practice in the field of IT, it’s not so common among the engineers working on modelling and simulations. Also, with increasing use of advanced AI and ML in the field of engineering, you’re seeing more engineers spending hours writing long lines of code, but not necessarily adopting version control using Git. So, this blog is an attempt to fill that gap and introduce non-IT experts to the concept of Git/Github. I will follow up in future blogs with some introductory tutorials to get started with the Git/Github.
Stay tuned!